Parametric statistics assume that the unknown CDF  belongs to a family of CDFs characterized by a parameter (vector)
belongs to a family of CDFs characterized by a parameter (vector)  . As the form of is assumed, the target of estimation is its parameters . Thus, all uncertainty about is comprised of uncertainty about its parameters. Parameters are estimated by
. As the form of is assumed, the target of estimation is its parameters . Thus, all uncertainty about is comprised of uncertainty about its parameters. Parameters are estimated by  , and estimates are be substituted into the assumed distribution to conduct inference for the quantities of interest. If the assumed distribution is incorrect, inference may also be inaccurate, or trends in the data may be missed.
, and estimates are be substituted into the assumed distribution to conduct inference for the quantities of interest. If the assumed distribution is incorrect, inference may also be inaccurate, or trends in the data may be missed.
To demonstrate the parametric approach, consider  independent and identically distributed random variables
independent and identically distributed random variables  generated from an exponential distribution with rate
generated from an exponential distribution with rate  . Investigators wish to estimate the 75
. Investigators wish to estimate the 75 percentile and erroneously assume that their data is normally distributed. Thus, is assumed to be the Normal CDF but
percentile and erroneously assume that their data is normally distributed. Thus, is assumed to be the Normal CDF but  and
and  are unknown. The parameters and
are unknown. The parameters and  are estimated in their typical way by
are estimated in their typical way by  and , respectively. Since the normal distribution belongs to the location-scale family, an estimate of the
and , respectively. Since the normal distribution belongs to the location-scale family, an estimate of the  percentile is provided by,
percentile is provided by,
![\[x_p = \bar{x} + s\Phi^{-1}(p)\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-c8f005ebb5cf4f30c04b8782038bdba6_l3.png "Rendered by QuickLaTeX.com")
where  is the standard normal quantile function, also known as the probit.
is the standard normal quantile function, also known as the probit.
set.seed(12345)
library(tidyverse, quietly = T)
# Generate data from Exp(2)
x <- rexp(n = 100, rate = 2)
# True value of 75th percentile with rate = 2
true <- qexp(p = 0.75, rate = 2)
true
## [1] 0.6931472
# Estimate mu and sigma
xbar <- mean(x)
s <- sd(x)
# Estimate 75th percentile assuming mu = xbar and sigma = s
param_est <- xbar + s * qnorm(p = 0.75)
param_est
## [1] 0.8792925
The true value of the 75 percentile of  is 0.69 while the parametric estimate is 0.88.
is 0.69 while the parametric estimate is 0.88.
Nonparametric statistics make fewer distributions about the unknown distribution , requiring only mild assumptions such as continuity or the existence of specific moments. Instead of estimating parameters of , itself is the target of estimation. is commonly estimated by the empirical cumulative distribution function (ECDF)  ,
,
![\[\hat{F}(x) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{I}(X_i \leq x).\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-4d7229ef76189b4c858b53669f9e7156_l3.png "Rendered by QuickLaTeX.com")
Any statistic that can be expressed as a function of the CDF, known as a statistical functional and denoted  , can be estimated by substituting for . That is, plug-in estimators can be obtained as
, can be estimated by substituting for . That is, plug-in estimators can be obtained as  .
.
Continue reading Parametric vs. Nonparametric Approach to Estimations
 ,
,  , the relationship between
, the relationship between  and
and  can be defined generally as
can be defined generally as![\[ y_i = m(x_i) + \varepsilon_i \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-78fa8d7d51d22115d6a1fe5a2c1bdf3b_l3.png "Rendered by QuickLaTeX.com")
![f(x_i) = E[y_i | x = x_i]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-cce0672391a02b3395ffd209d0d01d74_l3.png "Rendered by QuickLaTeX.com") and
and  . If we are unsure about the form of
. If we are unsure about the form of  , our objective may be to estimate
, our objective may be to estimate  . Here,
. Here,  and
and  . The true function
. The true function  is displayed in green.
is displayed in green.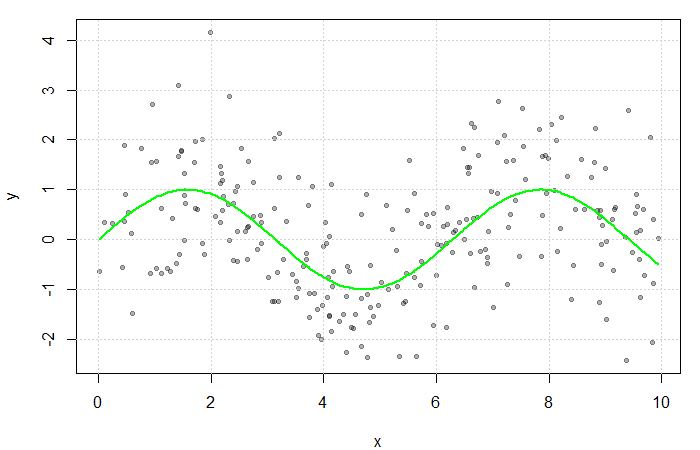
 could be estimated by averaging the value of the response at each
could be estimated by averaging the value of the response at each 
 at each
at each  . The fit is extremely rough due to gaps in
. The fit is extremely rough due to gaps in  for some bandwidth
for some bandwidth  . Then, a simple non-parametric estimate of
. Then, a simple non-parametric estimate of  can be constructed as average of the
can be constructed as average of the 
![\[ K(u) = \begin{cases} \frac{1}{2} & |u| \leq 1 \\ 0 & \text{o.w.} \end{cases} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-27c264e157b25fba34a6f4f7702c9ce2_l3.png "Rendered by QuickLaTeX.com")
 (see my previous blog bost). It is, however, convention to use kernel functions of degree
(see my previous blog bost). It is, however, convention to use kernel functions of degree  (e.g. the Gaussian and Epanechnikov kernels).
(e.g. the Gaussian and Epanechnikov kernels).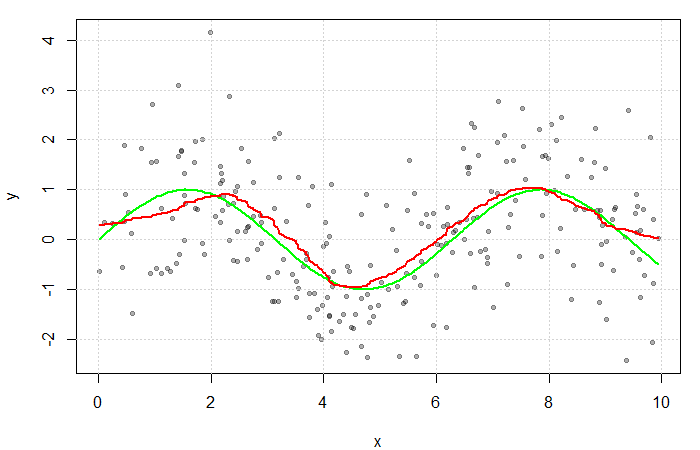
 . The green line represents the true function
. The green line represents the true function  .
.