Motivation
For observed pairs  ,
,  , the relationship between
, the relationship between  and
and  can be defined generally as
can be defined generally as
![\[ y_i = m(x_i) + \varepsilon_i \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-78fa8d7d51d22115d6a1fe5a2c1bdf3b_l3.png "Rendered by QuickLaTeX.com")
where ![f(x_i) = E[y_i | x = x_i]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-cce0672391a02b3395ffd209d0d01d74_l3.png "Rendered by QuickLaTeX.com") and
and  . If we are unsure about the form of
. If we are unsure about the form of  , our objective may be to estimate without making too many assumptions about its shape. In other words, we aim to “let the data speak for itself”.
, our objective may be to estimate without making too many assumptions about its shape. In other words, we aim to “let the data speak for itself”.
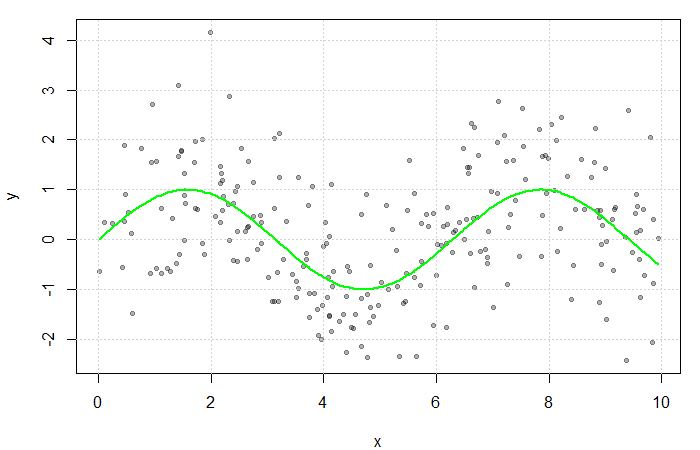
Simulated scatterplot of  . Here,
. Here,  and
and  . The true function
. The true function  is displayed in green.
is displayed in green.
Non-parametric approaches require only that be smooth and continuous. These assumptions are far less restrictive than alternative parametric approaches, thereby increasing the number of potential fits and providing additional flexibility. This makes non-parametric models particularly appealing when prior knowledge about ‘s functional form is limited.
Estimating the Regression Function
If multiple values of were observed at each ,  could be estimated by averaging the value of the response at each . However, since is often continuous, it can take on a wide range of values making this quite rare. Instead, a neighbourhood of is considered.
could be estimated by averaging the value of the response at each . However, since is often continuous, it can take on a wide range of values making this quite rare. Instead, a neighbourhood of is considered.
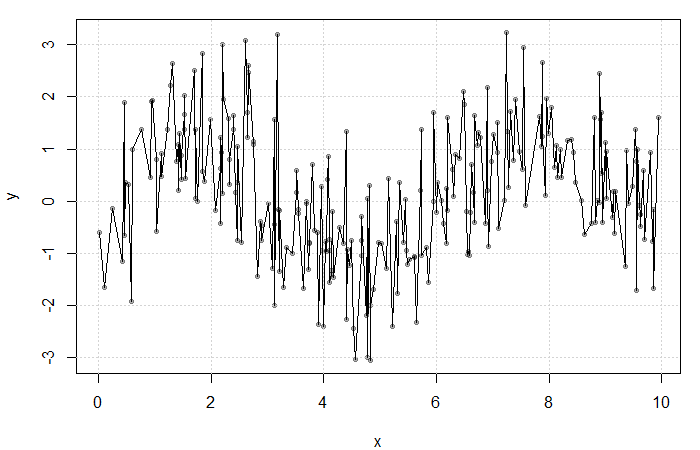
Result of averaging  at each
at each  . The fit is extremely rough due to gaps in and low frequency at each .
. The fit is extremely rough due to gaps in and low frequency at each .
Define the neighbourhood around as  for some bandwidth
for some bandwidth  . Then, a simple non-parametric estimate of
. Then, a simple non-parametric estimate of  can be constructed as average of the ‘s corresponding to the within this neighbourhood. That is,
can be constructed as average of the ‘s corresponding to the within this neighbourhood. That is,
(1) 
where
![\[ K(u) = \begin{cases} \frac{1}{2} & |u| \leq 1 \\ 0 & \text{o.w.} \end{cases} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-27c264e157b25fba34a6f4f7702c9ce2_l3.png "Rendered by QuickLaTeX.com")
is the uniform kernel. This estimator, referred to as the Nadaraya-Watson estimator, can be generalized to any kernel function  (see my previous blog bost). It is, however, convention to use kernel functions of degree
(see my previous blog bost). It is, however, convention to use kernel functions of degree  (e.g. the Gaussian and Epanechnikov kernels).
(e.g. the Gaussian and Epanechnikov kernels).
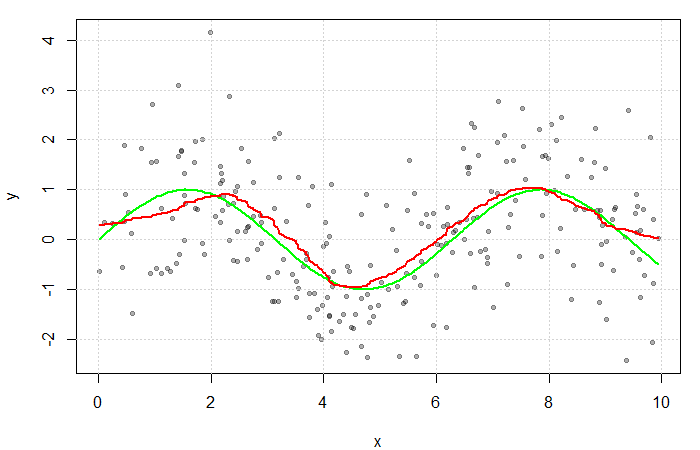
The red line is the result of estimating with a Gaussian kernel and arbitrarily selected bandwidth of  . The green line represents the true function
. The green line represents the true function  .
.
Kernel and Bandwidth Selection
The implementation of a kernel estimator requires two choices:
the kernel, , and
the smoothing parameter, or bandwidth,  .
.
Kernels are often selected based on their smoothness and compactness. We prefer a compact kernel to ensure that only data local to the point of interest is considered. The optimal choice, under some standard assumptions, is the Epanechnikov kernel. This kernel has the advantages of some smoothness, compactness, and rapid computation.
The choice of bandwidth is critical to the estimator’s performance and far more important than the choice of kernel. If the smoothing parameter is too small, the estimator will be too rough; but if it is too large, we risk smoothing out important function features. In other words, choosing involves a significant bias-variance trade-off.
 smooth curve, low variance, high bias
smooth curve, low variance, high bias
 rough curve, high variance, low bias
rough curve, high variance, low bias
The simplest way of selecting is to plot  for a range of different and pick the one that looks best. The eye can always visualize additional smoothing, but it is not easy to imagine what a less smooth fit might look like. For this reason, it is recommended that you choose the least smooth fit that does not show any implausible fluctuations.
for a range of different and pick the one that looks best. The eye can always visualize additional smoothing, but it is not easy to imagine what a less smooth fit might look like. For this reason, it is recommended that you choose the least smooth fit that does not show any implausible fluctuations.
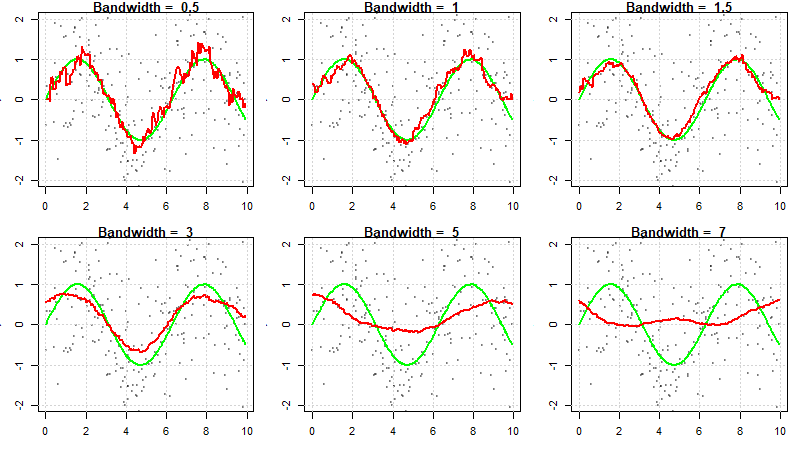
Kernel regression fits for various values of .
Cross-Validation Methods
Selecting the amount of smoothing using subjective methods requires time and effort. Automatic selection of can be done via cross-validation. The cross-validation criterion is
![\[ CV(\lambda) = \frac{1}{n} \sum_{n} \left( y_j - \hat{m}_{\lambda}^{(-j)} x_j \right)^2 \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-7f4d24c45778f5ea4249416c44cc2a97_l3.png "Rendered by QuickLaTeX.com")
where  indicates that point
indicates that point  is left out of the fit. The basic idea is to leave out observation and estimate based on the other
is left out of the fit. The basic idea is to leave out observation and estimate based on the other  observations. is chosen to minimize this criterion.
observations. is chosen to minimize this criterion.
True cross-validation is computationally expensive, so an approximation known as generalized cross-validation (GCV) is often used. GCV approximates CV and involves only one non-parametric fit for each value (compared to CV which requires  fits at each ).
fits at each ).
In order to approximate CV, it is important to note that kernel smooths are linear. That is,
![\[ \hat{Y} = \hat{m}_{\lambda}(x) = S_{\lambda} y \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-b20119299221ddd817df7de9e938e1a7_l3.png "Rendered by QuickLaTeX.com")
where  is an
is an  smoothing matrix. is analogous to the hat matrix
smoothing matrix. is analogous to the hat matrix  in parametric linear models.
in parametric linear models.
![\[ H = X(X^{T}X)^{-1}X^{T} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-754a6374c4a51fa568f66ad2a6d601e8_l3.png "Rendered by QuickLaTeX.com")
It can be shown that
![\[ CV(\lambda) = \frac{1}{n} \sum_{n} \left[ \frac{y_i - \hat{m}_{\lambda}(x_i)}{1 - s_{ii}(\lambda)} \right]^2 \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-847c01569a479e9c6c7010342aaf45a5_l3.png "Rendered by QuickLaTeX.com")
where  is the
is the  diagonal element of (hence
diagonal element of (hence  is analogous to
is analogous to  , the leverage of the observation). Using the smoothing matrix,
, the leverage of the observation). Using the smoothing matrix,
![\[ GCV(\lambda) = \frac{1}{n} \sum_{i=1}^{n} \left[ \frac{y_i - \hat{m}_{\lambda}(x_i)}{1 - \frac{\text{tr}(S_{\lambda})}{n}}\right] \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-295452051dd9e3eb95e4e77602325beb_l3.png "Rendered by QuickLaTeX.com")
where  is the trace of . In this sense, GCV is analogous to the influence matrix.
is the trace of . In this sense, GCV is analogous to the influence matrix.
Automatic methods such as CV often work well but sometimes produce estimates that are clearly at odds with the amount of smoothing that contextual knowledge would suggest. Therefore, it is essential to exercise caution when using them, and it is recommended that they be used as a starting point.