Introduction
At the end of my latest blog post, I promised that I would talk about how to perform constrained maximization using unconstrained optimizers. This can be accomplished by employing clever transformation and nice properties of maximum likelihood estimators – see this fantastic post from the now defunct 🙁 Econometrics Beat. Eventually I will get around to discussing more of the statistical details behind this approach and its implementation from scratch in R.
RIGHT NOW, I want to talk about how to obtain standard errors for Gaussian mixture model parameters estimated using the EM algorithm. So far, I’ve written two posts with respect to Gaussian mixtures and the EM algorithm:
- Embracing the EM algorithm: One continuous response, which motivates the theory behind the EM algorithm using a two component Gaussian mixture model; and
- EM Algorithm Essentials: Maximizing objective functions using R’s optim, which demonstrates how to implement log-likelihood maximization from scratch using the
optimfunction.
Both posts so far have focused only on POINT ESTIMATION! That is, obtaining estimates of our mixture model parameters.
Any estimate we obtain using any statistical method has some uncertainty associated with it. We quantify the uncertainty of a parameter estimate by its STANDARD ERROR. If we repeated the same experiment with comparable samples a large number of times, the standard error would reflect how much our estimates differ from experiment to experiment. Indeed, we would estimate the standard error as the standard deviation of the effect estimates across experiments. If we can understand how our estimates vary across experiments, i.e., estimate their standard errors, we can perform statistical inference by testing hypotheses or constructing confidence intervals, for example.
We usually do not need to conduct all of these experiments because theory tells us what form this distribution of effect estimates takes! We refer to this distribution as the SAMPLING DISTRIBUTION. When the form of the sampling distribution is not obvious, we may use resampling techniques to estimate standard errors. The EM algorithm, however, attempts to obtain maximum likelihood estimates (MLEs) which have theoretical sampling distributions. For well-behaved densities, MLEs can be shown to be asymptotically normally distributed and unbiased with a variance-covariance matrix equal to the inverse of the Fisher Information matrix, i.e., a function of the second derivatives of the log-likelihood or equivalently, the square of the first derivatives…
The tricky bit with the EM algorithm is we don’t maximize the observed log-likelihood directly to estimate Gaussian mixture parameters. Instead, we maximize a more convenient objective function. People much smarter than I have figured out this can give you the same answer. A question remains: if standard errors are estimated using the second derivative of the log-likelihood, but we used the objective function, how do we properly quantify uncertainty? Particularly as the derivatives of the log-likelihood are not straight-forward, for the same reasons that make optimization difficult.
Isaac Meilijson, another person smarter than me, provides us with a wealth of guidance in his 1989 paper titled A Fast Improvement to the EM Algorithm on its Own Terms (I love this title). In this blog post, we summarize and demonstrate how to construct simple estimators of the observed information matrix, and subsequently the standard errors of our EM estimates, when we have independent and identically distributed responses arising from a two-component Gaussian mixture model. Essentially, due to some nice properties, we can simply use the derivatives of our objective function, in lieu of our log-likelihood, to estimate the observed information. Standard errors computed using the observed information are then compared to those obtained using numerical differentiation of the observed log-likelihood.
 patients from a population, and examine the empirical density of their responses. We notice two modes, and based on prior knowledge, hypothesize that the density is actually a mixture of two Gaussian densities. For example, the density centered around greater responses may correspond to “healthy” patients and the other to “ill” patients. We would like to (1) estimate the probability of belonging to each subpopulation; and (2) estimate subpopulation parameters, e.g. mean response in among the healthy and ill. But, we have a problem: we don’t know who belongs to each subpopulation. In other words, subpopulation labels are unobserved or “latent.”
patients from a population, and examine the empirical density of their responses. We notice two modes, and based on prior knowledge, hypothesize that the density is actually a mixture of two Gaussian densities. For example, the density centered around greater responses may correspond to “healthy” patients and the other to “ill” patients. We would like to (1) estimate the probability of belonging to each subpopulation; and (2) estimate subpopulation parameters, e.g. mean response in among the healthy and ill. But, we have a problem: we don’t know who belongs to each subpopulation. In other words, subpopulation labels are unobserved or “latent.”
![\[f(y) = \pi~ f_1(y) + (1-\pi)~ f_2(y).\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-3ff6db8066295d806783429fdc8f487c_l3.png "Rendered by QuickLaTeX.com")
 , according to probability
, according to probability  and to the second, distributed per
and to the second, distributed per  , with probability
, with probability  . We assume both densities are Gaussian with respective means
. We assume both densities are Gaussian with respective means  and
and  and variances
and variances  and
and  .
.
 ,
,  , the relationship between
, the relationship between  and
and  can be defined generally as
can be defined generally as![\[ y_i = m(x_i) + \varepsilon_i \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-78fa8d7d51d22115d6a1fe5a2c1bdf3b_l3.png "Rendered by QuickLaTeX.com")
![f(x_i) = E[y_i | x = x_i]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-cce0672391a02b3395ffd209d0d01d74_l3.png "Rendered by QuickLaTeX.com") and
and  . If we are unsure about the form of
. If we are unsure about the form of  , our objective may be to estimate
, our objective may be to estimate  . Here,
. Here,  and
and  . The true function
. The true function  is displayed in green.
is displayed in green.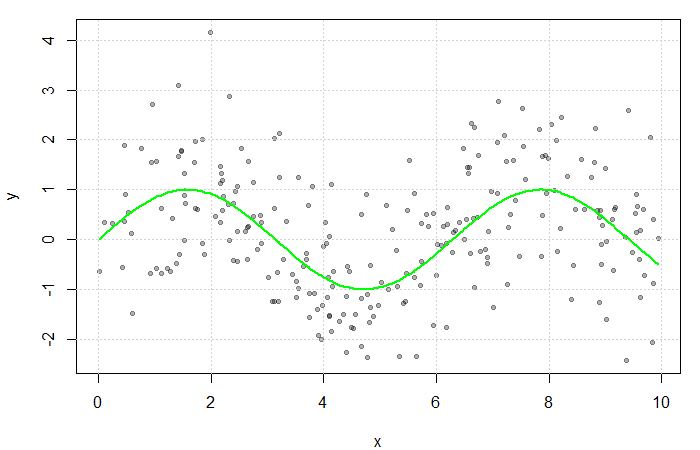
 could be estimated by averaging the value of the response at each
could be estimated by averaging the value of the response at each 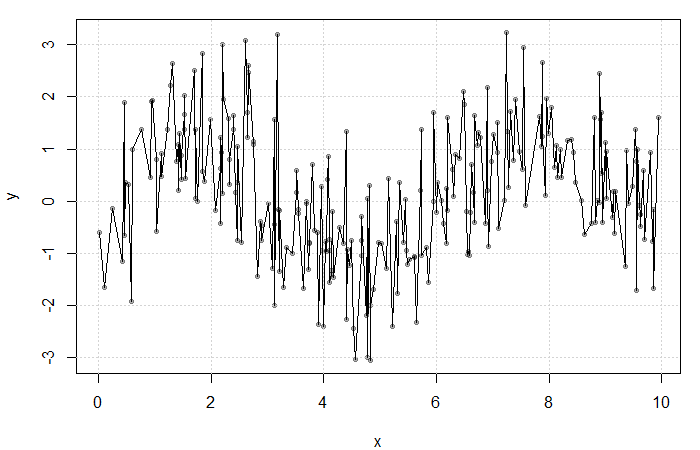
 at each
at each  . The fit is extremely rough due to gaps in
. The fit is extremely rough due to gaps in  for some bandwidth
for some bandwidth  . Then, a simple non-parametric estimate of
. Then, a simple non-parametric estimate of  can be constructed as average of the
can be constructed as average of the 
![\[ K(u) = \begin{cases} \frac{1}{2} & |u| \leq 1 \\ 0 & \text{o.w.} \end{cases} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-27c264e157b25fba34a6f4f7702c9ce2_l3.png "Rendered by QuickLaTeX.com")
 (see my previous blog bost). It is, however, convention to use kernel functions of degree
(see my previous blog bost). It is, however, convention to use kernel functions of degree  (e.g. the Gaussian and Epanechnikov kernels).
(e.g. the Gaussian and Epanechnikov kernels).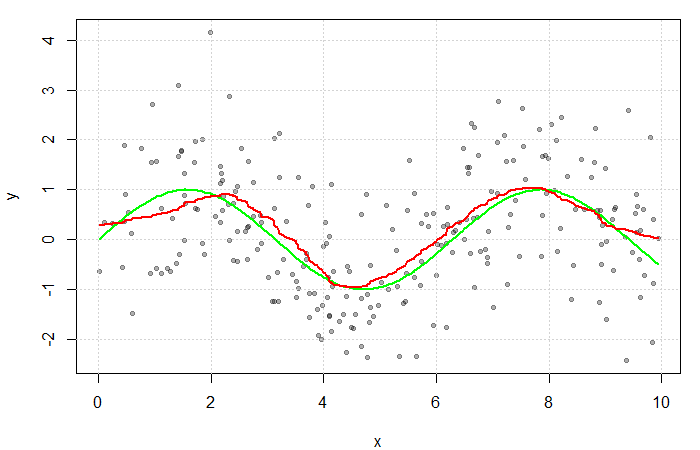
 . The green line represents the true function
. The green line represents the true function  .
.