To start, I apologize for this blog’s title but I couldn’t resist referencing to the Owen Wilson classic You, Me, and Dupree – wow! The other gold-plated candidate was U-statistics and You. Please, please, hold your applause.

My previous blog post defined statistical functionals as any real-valued function of an unknown CDF,  , and explained how plug-in estimators could be constructed by substituting the empirical cumulative distribution function (ECDF)
, and explained how plug-in estimators could be constructed by substituting the empirical cumulative distribution function (ECDF)  for the unknown CDF
for the unknown CDF  . Plug-in estimators of the mean and variance were provided and used to demonstrate plug-in estimators’ potential to be biased.
. Plug-in estimators of the mean and variance were provided and used to demonstrate plug-in estimators’ potential to be biased.
![\[ \hat{\mu} = \mathbb{E}_{\hat{F}_n}[X] = \sum_{i=1}^{n} X_i P(X = X_i) = \frac{1}{n} \sum_{i=1}^{n} X_i = \bar{X}_{n} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-1c4166355261af485d335606b1d858c2_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{\sigma}^{2} = \mathbb{E}_{\hat{F}_{n}}[(X- \mathbb{E}_{\hat{F}_n}[X])^2] = \mathbb{E}_{\hat{F}_n}[(X - \bar{X}_{n})^2] = \frac{1}{n} \sum_{i=1}^{n} (X_i - \bar{X}_{n})^2. \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-1ae64559278ccc7ec2f0dd38d1713032_l3.png "Rendered by QuickLaTeX.com")
Statistical functionals that meet the following two criteria represent a special family of functionals known as expectation functionals:
1) is the expectation of a function  with respect to the distribution function ; and
with respect to the distribution function ; and
![\[ T(F) = \mathbb{E}_{F} ~g(X)\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-7bfa10261fdefb6ccf03459f369fae39_l3.png "Rendered by QuickLaTeX.com")
2) the function  takes the form of a symmetric kernel.
takes the form of a symmetric kernel.
Expectation functionals encompass many common parameters and are well-behaved. Plug-in estimators of expectation functionals, named V-statistics after von Mises, can be obtained but may be biased. It is, however, always possible to construct an unbiased estimator of expectation functionals regardless of the underlying distribution function . These estimators are named U-statistics, with the “U” standing for unbiased.
This blog post provides 1) the definitions of symmetric kernels and expectation functionals; 2) an overview of plug-in estimators of expectation functionals or V-statistics; 3) an overview of unbiased estimators for expectation functionals or U-statistics.
 . As the form of
. As the form of  , and estimates are be substituted into the assumed distribution to conduct inference for the quantities of interest. If the assumed distribution
, and estimates are be substituted into the assumed distribution to conduct inference for the quantities of interest. If the assumed distribution  independent and identically distributed random variables
independent and identically distributed random variables  generated from an
generated from an  . Investigators wish to estimate the 75
. Investigators wish to estimate the 75 percentile and erroneously assume that their data is normally distributed. Thus,
percentile and erroneously assume that their data is normally distributed. Thus,  and
and  are unknown. The parameters
are unknown. The parameters  are estimated in their typical way by
are estimated in their typical way by  and
and  percentile is provided by,
percentile is provided by,![\[x_p = \bar{x} + s\Phi^{-1}(p)\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-c8f005ebb5cf4f30c04b8782038bdba6_l3.png "Rendered by QuickLaTeX.com")
 is the standard normal quantile function, also known as the
is the standard normal quantile function, also known as the  is 0.69 while the parametric estimate is 0.88.
is 0.69 while the parametric estimate is 0.88. ,
,![\[\hat{F}(x) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{I}(X_i \leq x).\]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-4d7229ef76189b4c858b53669f9e7156_l3.png "Rendered by QuickLaTeX.com")
 , can be estimated by substituting
, can be estimated by substituting  .
. ,
,  , the relationship between
, the relationship between  and
and  can be defined generally as
can be defined generally as![\[ y_i = m(x_i) + \varepsilon_i \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-78fa8d7d51d22115d6a1fe5a2c1bdf3b_l3.png "Rendered by QuickLaTeX.com")
![f(x_i) = E[y_i | x = x_i]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-cce0672391a02b3395ffd209d0d01d74_l3.png "Rendered by QuickLaTeX.com") and
and  . If we are unsure about the form of
. If we are unsure about the form of  , our objective may be to estimate
, our objective may be to estimate  . Here,
. Here,  and
and  . The true function
. The true function  is displayed in green.
is displayed in green.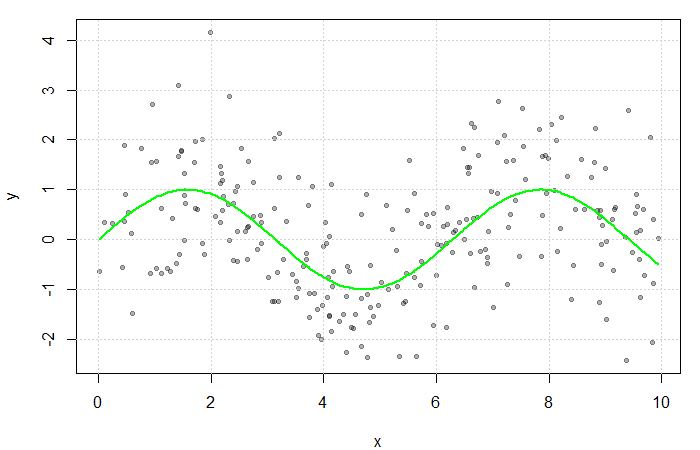
 could be estimated by averaging the value of the response at each
could be estimated by averaging the value of the response at each 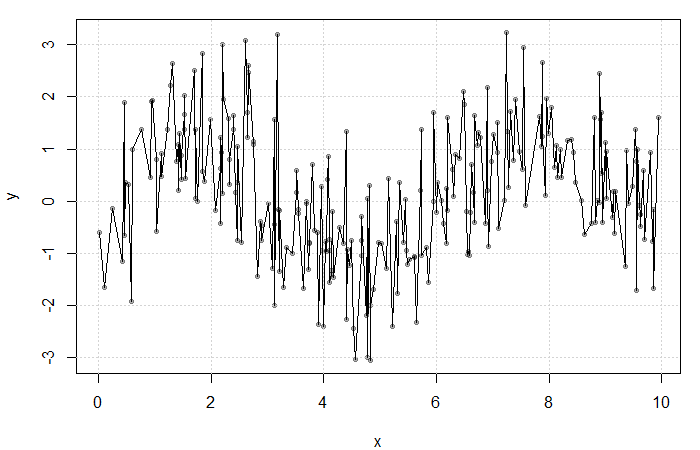
 at each
at each  . The fit is extremely rough due to gaps in
. The fit is extremely rough due to gaps in  for some bandwidth
for some bandwidth  . Then, a simple non-parametric estimate of
. Then, a simple non-parametric estimate of  can be constructed as average of the
can be constructed as average of the 
![\[ K(u) = \begin{cases} \frac{1}{2} & |u| \leq 1 \\ 0 & \text{o.w.} \end{cases} \]](https://statisticelle.com/wp-content/ql-cache/quicklatex.com-27c264e157b25fba34a6f4f7702c9ce2_l3.png "Rendered by QuickLaTeX.com")
 (see my previous blog bost). It is, however, convention to use kernel functions of degree
(see my previous blog bost). It is, however, convention to use kernel functions of degree  (e.g. the Gaussian and Epanechnikov kernels).
(e.g. the Gaussian and Epanechnikov kernels).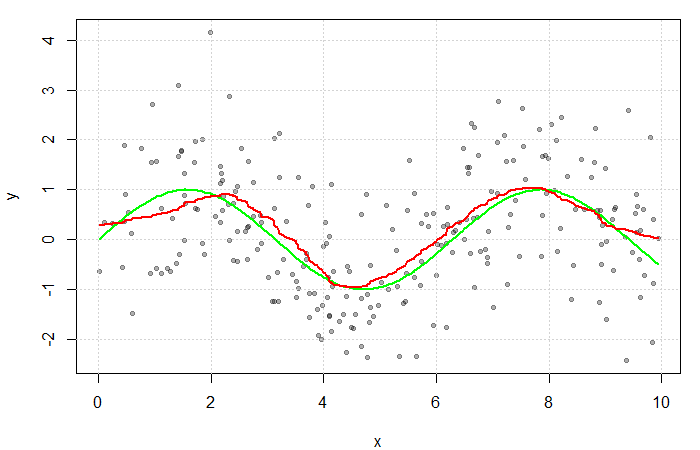
 . The green line represents the true function
. The green line represents the true function  .
.